")
")
Metamodel (Ecore) Design Checklist - part 1
Be meticulous with the model describing your domain! So many aspects of your tool will trickle down from your Ecore model that it pays a lot to pause for a bit and do some basic sanity checks.
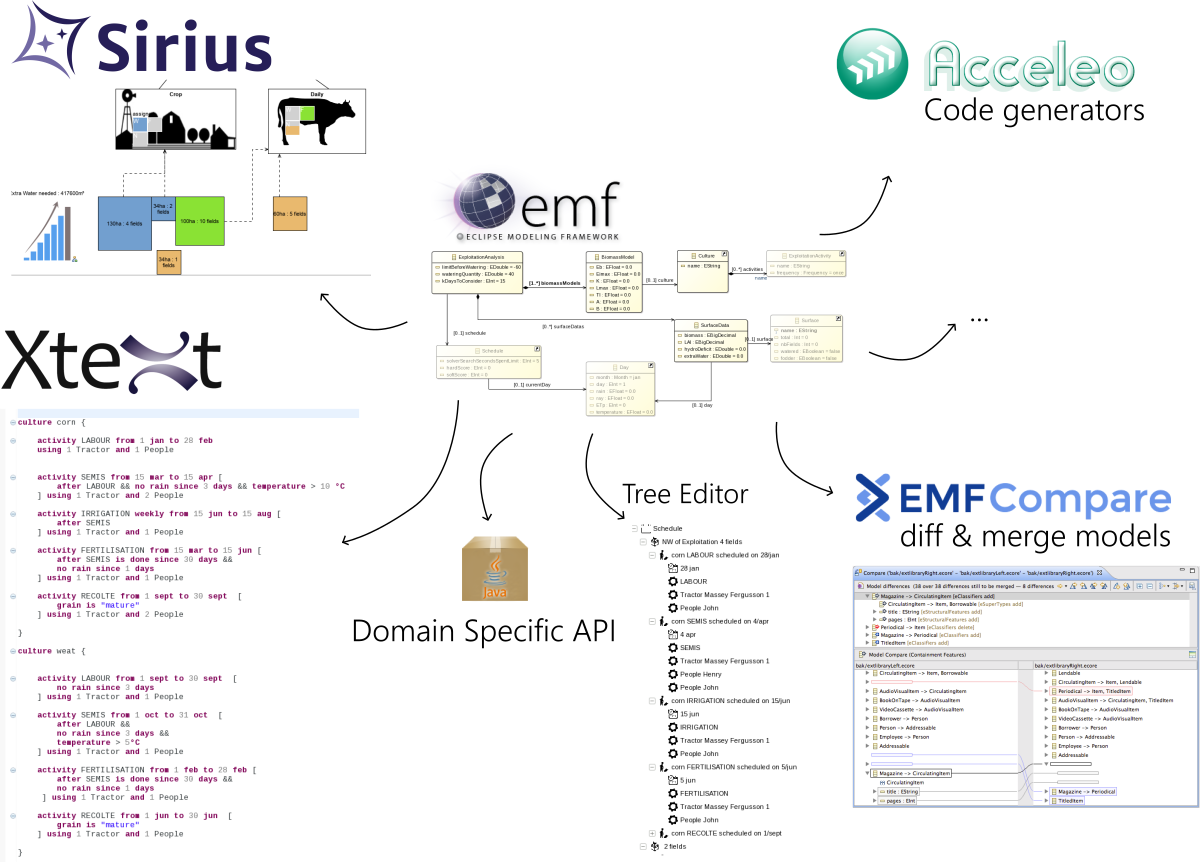 The Ecore model in the center is the basis for so many things!
The Ecore model in the center is the basis for so many things!
Eclipse Modeling technologies are enabling you to build graphical, tree or textual editors, connectors to import or export data, code generators and all of these features in your tool are directly tied or infered from an Ecore model. Better get it right.
I compiled the following checklist based on my personal experience, this is not exhaustive and I expect it to live and get richer over time.
Most of the checks stated here are very easy to comply with when considered from the start. When it’s later down the road the gain/risk ratio should be evaluated as some changes might need to update some code, some files or might just be too much work to be worth it then. Because of this and because we sometime learned the hard way you might quite easily find some Ecore models I authored which are not 100% compliant with this list ;).
By the way, feel free to tell me about your own rules, I might add it to the list!
Ground rules
☑ The purpose and audience of the models are stated
A model is a representation of a system for a given purpose. Just like Object Oriented Programming never was intended to help “structuring code so that it’s close to the real world” a metamodel doesn’t have to match the real world.
On the other hand, a metamodel should answer a specific set of questions. Start by stating those questions. And for who.
The “who” is using the model as this might have important implications regarding the naming of the concepts. My tool of chocie for defining the “who” is to take a few minutes and write down a Persona so that I can get back at it when I need to justify a given choice. The persona description should document the user background, the vocabulary he is confortable with and the tools he is used too.
Example: Models from this metamodel will enable researcher in agriculture to answer the questions: how many resources (water, machines, humans) are needed for a given farm structure, in a given region, and for set of cultures (wheat, sorgho..).
Example: Models from this metamodel will enable software architects to answer the questions: which are the services existing in my system, what are their non-functional characteristics, their signature, who owns them and how are the related to each others ?

or even
Example: Models from this metamodel will enable My Little Pony authors to answer the questions how are the story and the characters evolving during the show, when is each character introduced and is it consistent with the episodes previously aired ?
☑ The nsURI is the definitive one and is consistent with your naming conventions
As part of this first step of setting up an identification card for your metamodel, you have to stop for a minute coming up with the EPackage nsURI. This nsURI will identify your Ecore model, starting now and forever. It is used in many places, in the generated Java code, in the plugin.xml file of your project, but more importantly other tools or Ecore models are likely to use this URI to identify your Ecore model (in code generators, model transformers…).
Changing this is a pain. Make sure the nsURI you picked is sensible and matches your naming conventions in this regard.
The most important thing is to be consistent and that’s not a given; see how we fail in having a consistent naming in Eclipse itself.
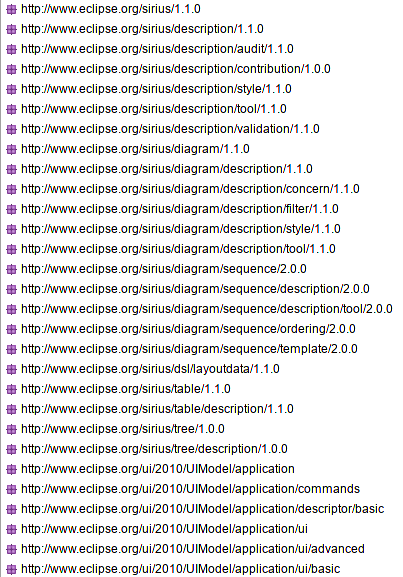 NsUris in the modeling package.
NsUris in the modeling package.
The same level of care should be used for your project name. Make sure you get it right quickly or be prepared for fiddling with identifiers in many different files.
☑ Nested EPackages are not used
There is no such thing as a sub-EPackage. Let’s just pretend this capability never existed in Ecore (and by the way, you can’t do this in Xcore).
— Comment #4 from Ed Merks This email address is being protected from spambots. You need JavaScript enabled to view it. — Yes, that simply doesn’t work. It’s not possible to represent nested Ecore Package in Xcore.
Allowing the definition of subpackages within an EPackage was, in retrospect, a bad decision as that introduced several different ways to reference a single domain. We should have a one to one mapping in between a domain and an EPackage, this one clearly identified by its nsURI. The notion of nested EPackage break this mapping as then you have several different ways to access an EPackage. This lead to slightly different intepretation of this among tools, one might declare a subpackage if a parent is declared, or the other way around, or not at all.
In a nutshell, one EPackage, one .ecore file, and your life will be simpler.
☑ Names are real ones, precise and consistent
Naming things is hard, and just like in every design activity it is of the most critical importance. For non-native english speakers it gets even harder as we might lack some vocabulary or some subtle interpretation might escape us.
![]()
Tips and tricks :
use PowerThesaurus, make sure the name is the most precise you can get. use the user background to pick the right name (having defined the Persona comes in handy) try to avoid names which are so general or abstract that they could be interpreted in many different ways by your target users. Artifact, Element are probably fairly bad names (but again, use the context to decide).in the MyLittlePony world an Element refers to the “Elements of Harmony” and has a very precise definition. The context matters.
☑ Reference and attribute names are consistent
Check that you stick with a consistent convention for your references. The main decisions which are in front of you:
do you pluralize the references with a many upper bound ? do you add a prefix like owned for any containment reference? do you add a prefix like parent for any container reference? do you add a prefix for any derived reference or attribute?☑ All the non-abstract EClasses are supposed to be instanciated
In the very early phases it often happens that you start with a concept as an EClass and at some point you specialized it, in the end you have an abstract EClass but you just forgot to make it abstract, leading to the possibility to instanciate it.
Hold on, go through all the concepts which you don’t want to be instanciable and make sure they are “abstract” or “interface”.
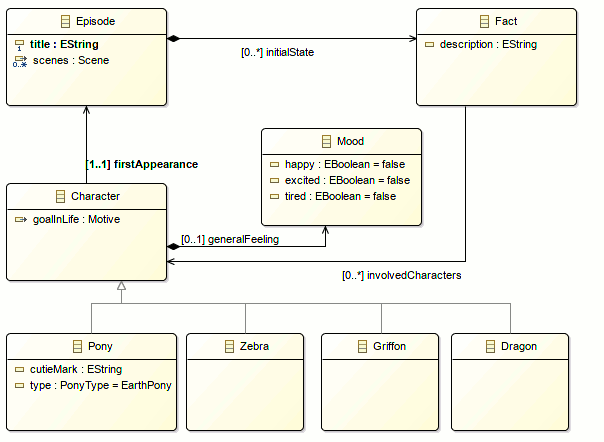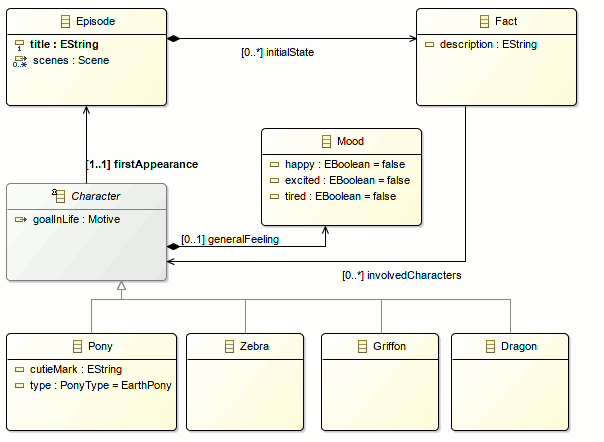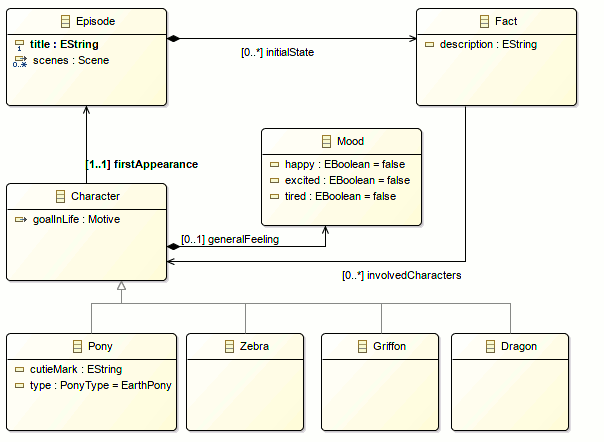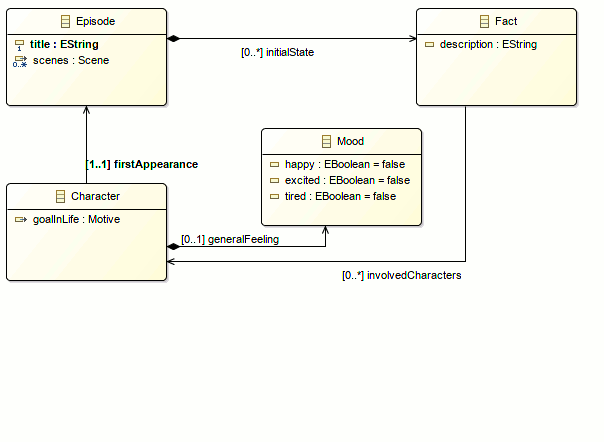 Introducing subclasses
Introducing subclasses
☑ 0..1 and 1..1 cardinalities have been reviewed
Go through all the attributes and reference and think again: does an instance makes any sense if this attribute is not valued ?
 EcoreTools uses bold typefaces for any required element
EcoreTools uses bold typefaces for any required element
☑ Containment relationships have been reviewed
Ecore provides a notion of containment reifying the basic lifecycle of an instance. If an object A is contained in an object B then whenever the object B is removed or deleted the object ‘A’ is too. Thinking about your model as a tree helps in those cases: either your object is expected to be a the root of a resource or it has to be contained by another object.
The goal here is to make a conscious decision about when should an instance disappear from the model and clearly identify the type of elements you expect as a root of a model file.
Also note that this containment relationship might be leveraged as part of the referencing of an element.
☑ Every validation rule which is not enforced by the Ecore model structure itself is named.
While designing capture and name every validation rule which comes up. You should be able to come up with a name and hopefully a description of valid and invalid cases.
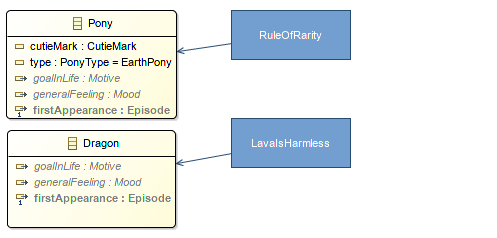 Constraints annotations in EcoreTools.
Constraints annotations in EcoreTools.
☑ The concepts are all documented.
Make sure you have documented all the EClasses or relationship which are not completely obvious. We use annotations directly in Ecore to capture the developper or specifier facing documentation.
 Design doc annotation can be added in a diagram using EcoreTools
Design doc annotation can be added in a diagram using EcoreTools
 A table editor is also provided for convenience
A table editor is also provided for convenience
Note that you can also value an attribute in the Genmodel for the user documentation and that this information will be directly used by EMF in the tree editor.
☑ There are no Boolean monsters in the making
Over time a simple EClass with a couple of EAttributes can grow to a monster with many more, each one acting as a configuration “flag”. Identify such monsters in the making. Go through all the possible combinations of attribute values and make sure they are all valid, also confirm that there is only two possible outcomes: true or false, but not more. Sometimes a couple of EEnumerations are better to capture the transversal characteristics.
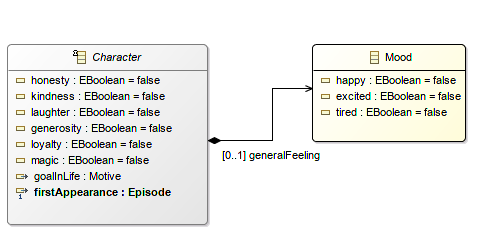 Booleans monster
Booleans monster
Also check your boolean attributes naming. The EMF Java generator will add an “is” prefix on your API, you don’t have to do it, but make sure isMyName is legible.
Outside world
☑ I decided how instances should be referenced from the outside
Any EObject which is contained in a resource has a URI and might be referenced by others. But there are so many ways to identify an instance. You roughly have to decide in between: Resource specific identification like XMI-IDs, or domain related identification by defining an id EAttribute or by using the EReference eKeys.
The default behavior uses the containment relationship and the index of the object within it’s containing reference. This solution is not suitable for 99% of the cases as any addition or removal in a reference might break references (but this is the default one in EMF as it is the only one which assumes nothing about the serialization format or the EClasses).
 EcoreTools will display the eKey with a small blue label on the target end
EcoreTools will display the eKey with a small blue label on the target end
☑ A user can’t introduce cyclic references in between model fragments

If you are planning to split your model on multiple files or if part of it is to be referenced by other models, then you should make sure that introducing such references is not supposed to modify the referenced instance. These situations can easily arise when using EOpposite references.
Keep in mind that many EMF technologies will provides you with a way to easily and efficiently navigate on inverse references which are not designed as such in the Ecore model.
For instance using Sirius you might write queries like: aql:self.eInverse(some::Type) to retrieve any instance of Type referencing the object self or aql:self.eInverse(anEReferenceName) to navigate on the inverse of the reference anEReferenceName from the objeect self.
☑ The dependencies in between EPackages are in control
Inheritance or references in between EPackages can quickly get tricky (and the former even sooner than the later). It is so easy to do using the modeling tools that one can easily abuse it, but in the end your Ecore model is translated to Java and OSGi components, you’ll have to deal with the technical coordination.
As such, only introduce inter-EPackage relationships for compelling reasons and when you do, make sure you either only reference EClasses or if you need to subclass make sure you are able to cope with a strong coupling on the corresponding component.
 Package dependencies diagram in EcoreTools
Package dependencies diagram in EcoreTools
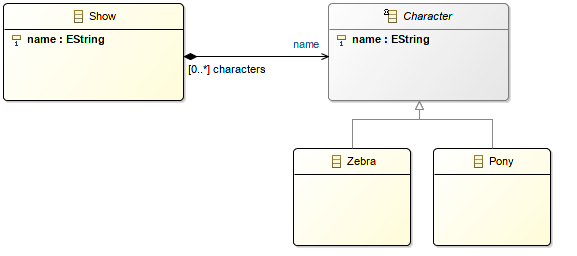
☑ The EClasses which might be extended by subtypes are clearly identified
This item is symetric from the previous one: if one of your goal is for others to provide subtypes of your EClasses explicitely design for it and document it.
That’s it for now but the subject is far from being exhausted. The next part will be more technical with a focus on the scalability and on the mapping in between Ecore and Java. Follow me on Twitter to know when it gets published. In the meantime feel free to give your feedback!
Metamodel (Ecore) Design Checklist - part 1 was originally published by Cédric Brun at CTO @ Obeo on May 02, 2016.